Mobile App Users
Tracking mobile app users through a Tableau dashboardOverview
This analysis starts by cleaning, partitioning and classifying the user activity data derived from the text file logs the music application generates. The data pipeline to pull raw log data is managed using Python and Lambda functions in AWS. These pipelines partition and deposit clean log data into a S3 Data Lake. From there, another Python script run in Lambda creates on-demand EMR clusters to run ETL processes on this raw app log data and create a “data lakehouse” that can be used for reporting by combining S3, Glue and Athena.
The front end of this visualisation uses Tableau to combine user data derived from logs with user data from partner systems to segment and analyse user acquisition, user retention and user activity. Deployed to Tableau Server for company-wide access.
Analytical Concepts
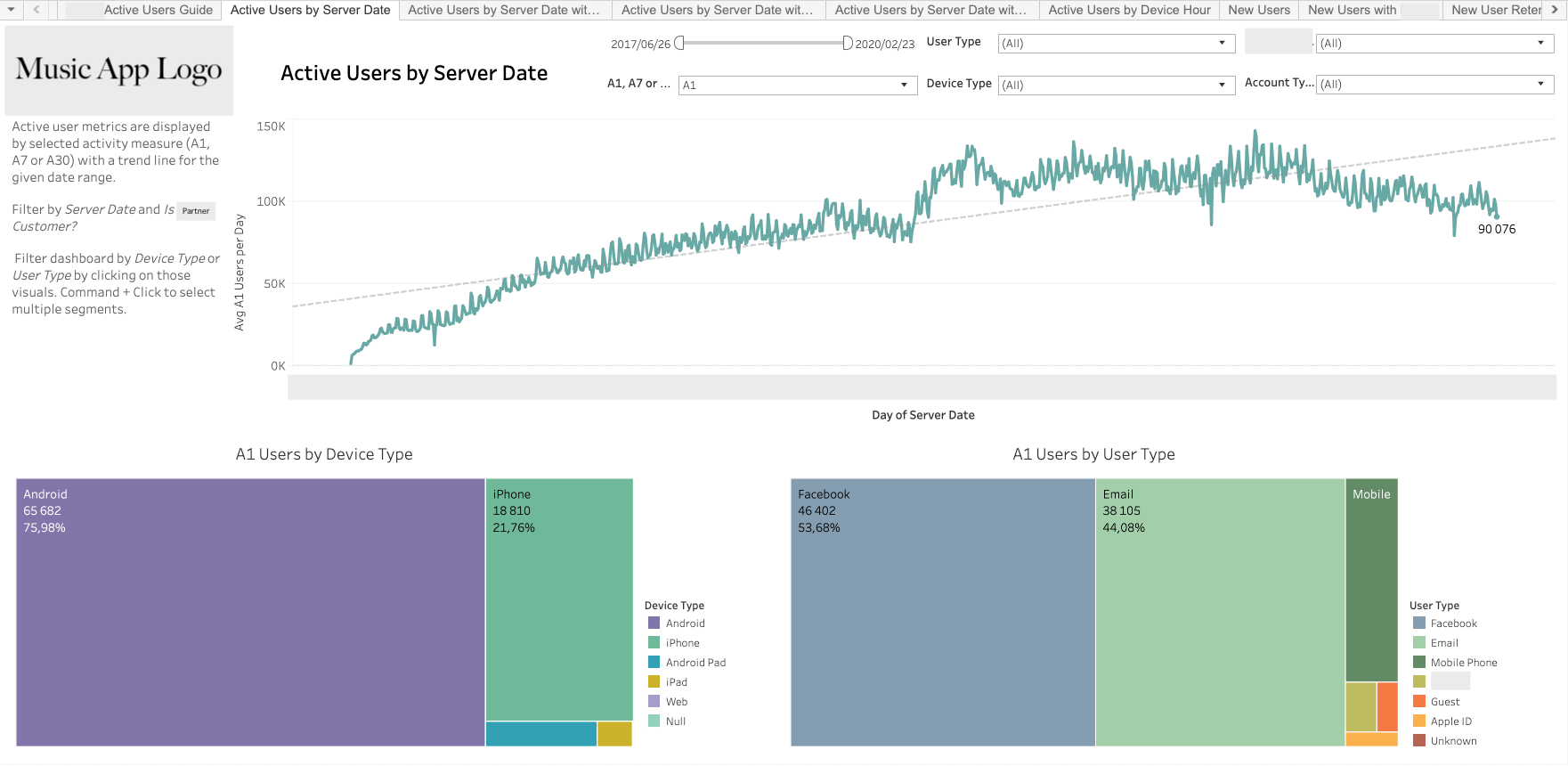
- Daily Active Users
- Weekly Active Users
- Monthly Active Users
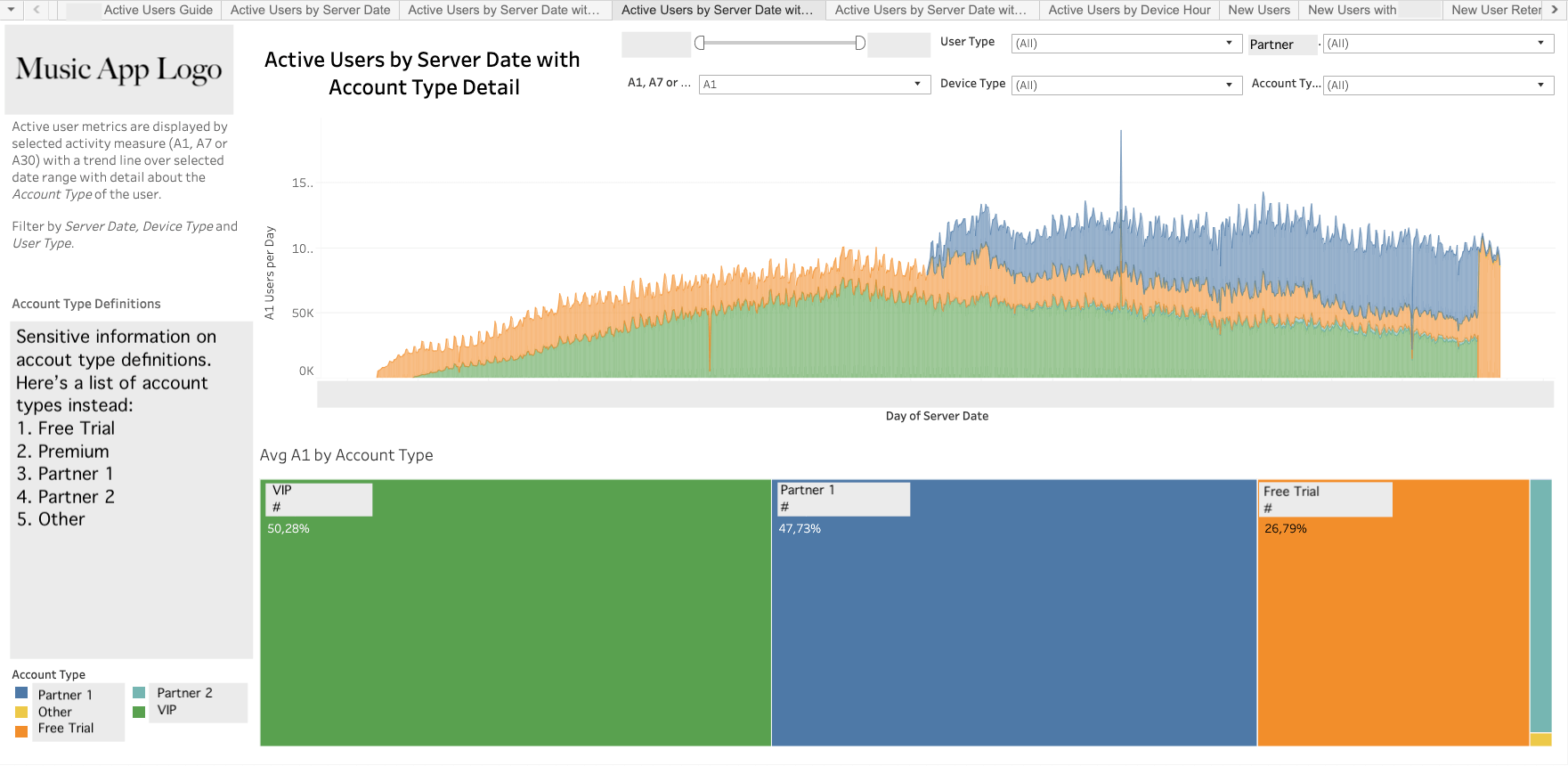
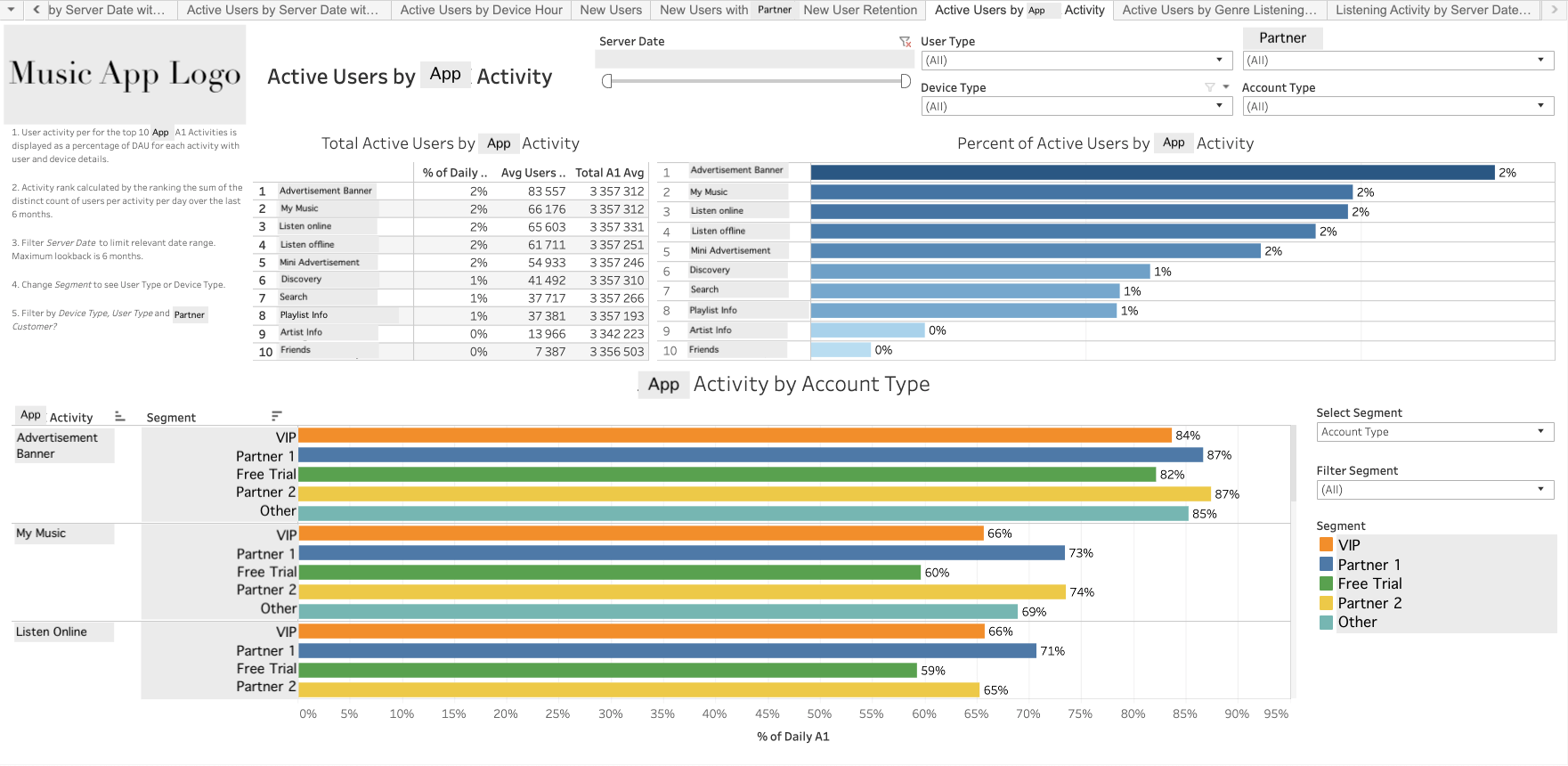
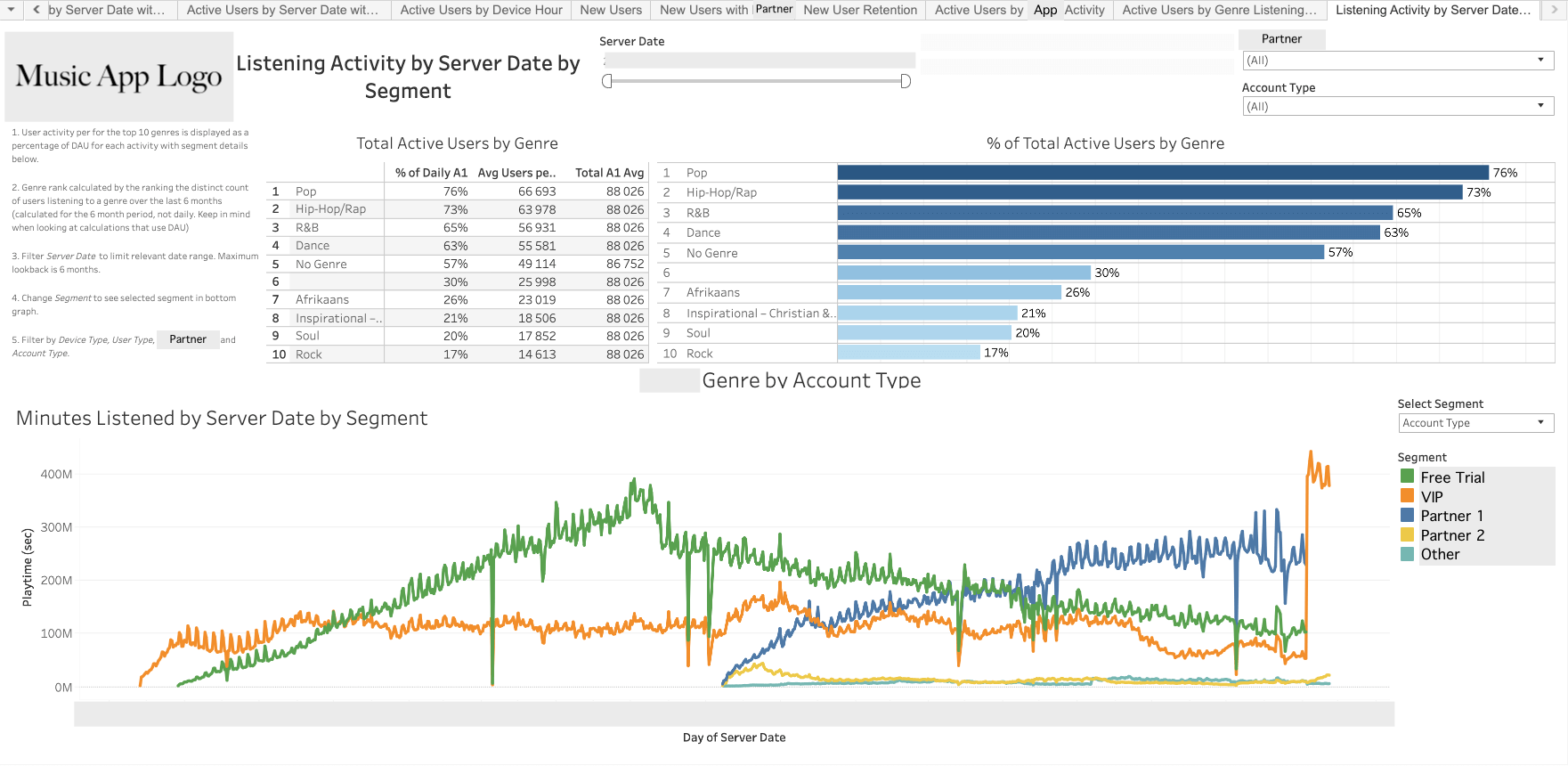
- User Segmentation
- User Retention
- User Churn
Data Stack
- Python
- AWS Lambda
- AWS Glue
- AWS EMR
- AWS S3
- AWS Athena
- SQL
- Tableau